Agentic BI für KMU in der Praxis: Ein Schweizer SaaS-Fall mit nao
Agentic BI bedeutet, dass KI-Agenten Geschäftsfragen autonom beantworten, indem sie die richtigen Daten finden, SQL schreiben, Ergebnisse prüfen und begründete Antworten liefern. In diesem Beitrag zeigen wir am konkreten Beispiel der fiktiven PulsCheck AG, wie ein produktionsnaher Aufbau mit dem Open-Source-Framework nao aussieht - inklusive Datenmodell, Context Stack, Test-Suite und typischen Stolperfallen.

Stand: Mai 2026 · Autor: Thomas Ebermann · Lesedauer: ca. 18 Minuten
Hinweis zur Fallstudie: Das im Folgenden beschriebene Unternehmen „PulsCheck AG” ist ein fiktives zusammengesetztes Beispiel, das auf wiederkehrenden Mustern aus realen Schweizer KMU-Projekten basiert. Geschäftsmodell, Datenstruktur, Code und Ergebnisse sind plausibel und nachvollziehbar, aber bewusst nicht einer einzelnen Kundin zugeordnet, um Vertraulichkeit zu wahren.
Tools, die in diesem Beitrag verwendet werden: nao Open-Source Analytics Agent (MIT-Lizenz) Für den Praxisteil nutzen wir DuckDB als analytische Engine – eine eingebettete OLAP-Datenbank, die nao nativ unterstützt. Damit lässt sich der gesamte Aufbau lokal nachvollziehen, ohne dass ein Cloud-Warehouse oder ein Postgres-Server benötigt wird.
TL;DR - Und wie das Endresultat aussieht
Agentic BI bedeutet, dass KI-Agenten Geschäftsfragen autonom beantworten, indem sie die richtigen Daten finden, SQL schreiben, Ergebnisse prüfen und begründete Antworten liefern. In diesem Beitrag zeigen wir am konkreten Beispiel der fiktiven PulsCheck AG, wie ein produktionsnaher Aufbau mit dem Open-Source-Framework nao aussieht – inklusive Datenmodell, Context Stack, Test-Suite und typischen Stolperfallen. Anschliessend ordnen wir ein, wann nao die richtige Wahl ist und wann eine der etablierten Alternativen (Snowflake Cortex Analyst, Power BI Copilot, Sigma Computing, ThoughtSpot, Basejump AI oder BlazeSQL) besser passt.
Die Kernerkenntnis vorweg: Der Agent ist nicht das Schwierige. Der Semantic Layer und der Context Stack sind es. Wenn diese stehen, läuft der Rest in überschaubarer Zeit.
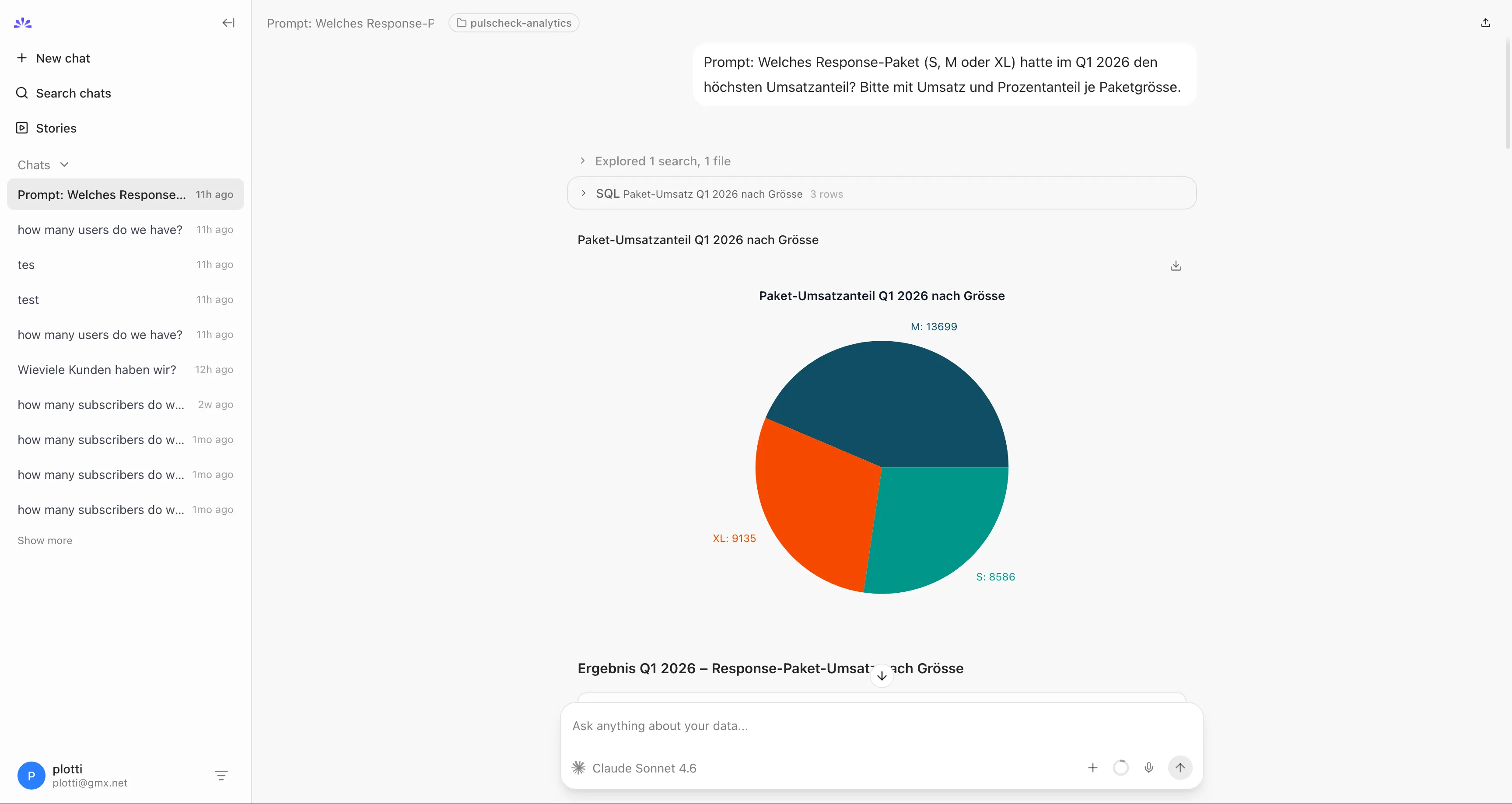
Und schon mal vorab so kann das Resultat in nao aussehen:
Was ist Agentic BI – kurz
Agentic BI bezeichnet Systeme, in denen ein KI-Agent autonom Datenanalyse-Aufgaben übernimmt: Er versteht eine Geschäftsfrage in natürlicher Sprache, identifiziert die relevanten Tabellen, formuliert die SQL-Abfrage, prüft das Ergebnis auf Plausibilität und liefert eine begründete Antwort zurück. Anders als ein Dashboard, das Sie konsultieren müssen, oder ein Chatbot, der mit Ihren Daten Smalltalk macht, handelt der Agent zielgerichtet auf Basis Ihrer Geschäftslogik.
Drei Abgrenzungen, die häufig verwischt werden:
- Klassische BI ist Pull-Reporting. Sie öffnen ein Dashboard, das jemand vorher gebaut hat.
- AI-Copiloten in Power BI oder Tableau erklären bestehende Charts und beantworten einfache Fragen innerhalb der Plattform.
- Generische Chatbots („ChatGPT auf Ihre Daten”) halluzinieren ohne strukturierten Zugriff auf Geschäftslogik regelmässig Definitionen oder Joins.
Agentic BI sitzt darüber: Der Agent kann eigene SQL-Pfade entwerfen, mehrere Schritte planen, Zwischenergebnisse prüfen und seine Antwort begründen. Snowflake formuliert das in einem Engineering-Blog-Beitrag von 2024 als „agentic AI system, coupled with a semantic model” – ein Setup, das laut Snowflakes interner Evaluation auf realen BI-Use-Cases 90 Prozent SQL-Genauigkeit überschreitet. Diese Genauigkeit hängt allerdings massgeblich von der Qualität des Semantic Layers ab – nicht vom Modell.
Der Fall: PulsCheck AG
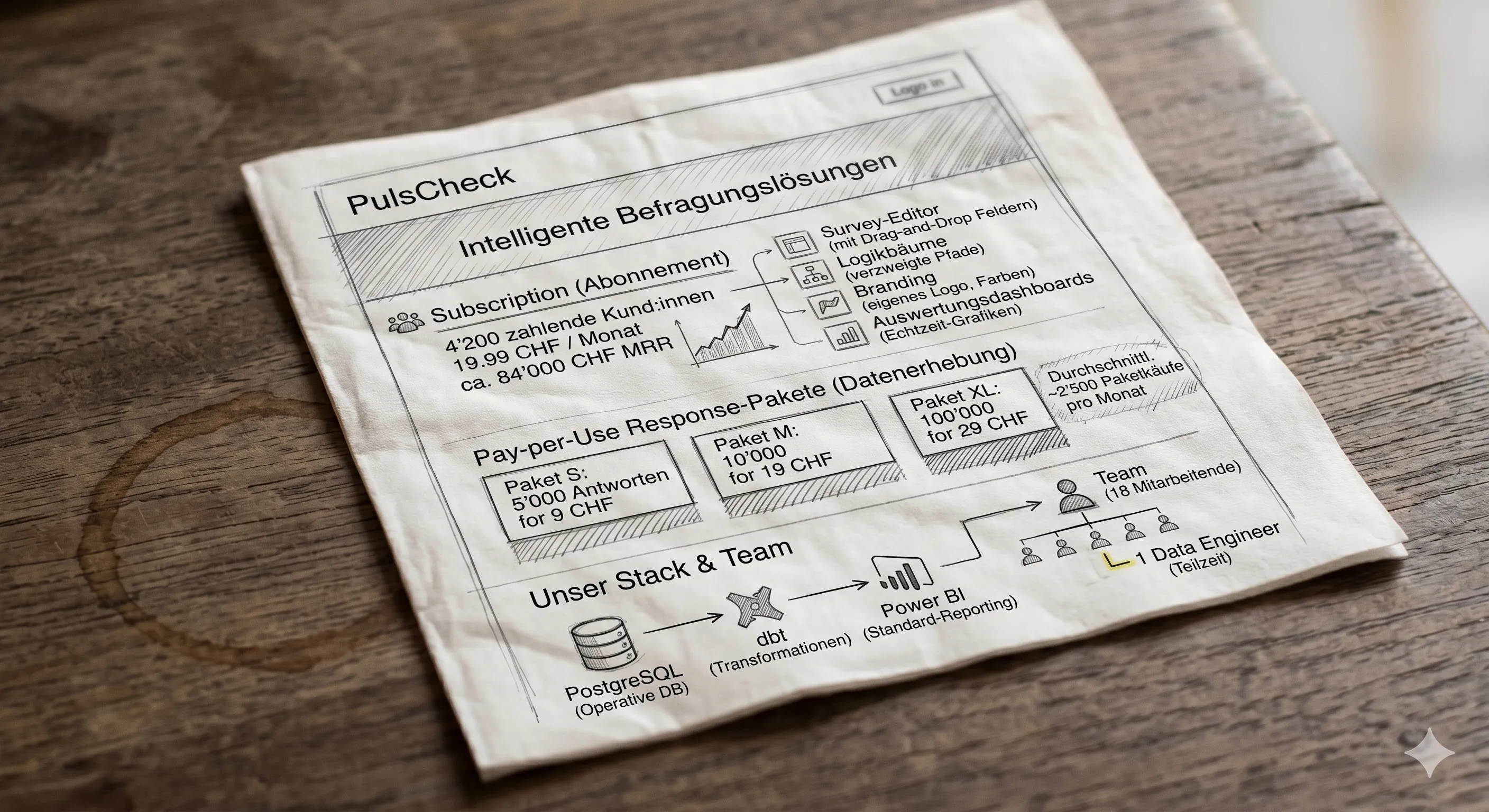
PulsCheck ist ein fiktiver Zürcher SaaS-KMU – eine Schweizer Online-Befragungsplattform, vergleichbar mit SurveyMonkey, mit Fokus auf DACH-Märkte und mehrsprachiger Befragungsführung (DE/FR/IT/EN). Das Geschäftsmodell ist hybrid:
- Subscription: 4’200 zahlende Kund:innen zu 19.99 CHF/Monat → ca. 84’000 CHF MRR. Damit erhalten sie Zugriff auf den Survey-Editor, Logikbäume, Branding und Auswertungsdashboards.
- Pay-per-Use Response-Pakete: Drei Grössen für die tatsächliche Datenerhebung – S (5’000 Antworten für 9 CHF), M (10’000 für 19 CHF), XL (100’000 für 29 CHF). Im Schnitt rund 2’500 Paketkäufe pro Monat.
- Stack: PostgreSQL als operative DB, dbt für Transformationen, Power BI für Standard-Reporting.
- Team: 18 Mitarbeitende, davon ein Data Engineer in Teilzeit.
Die Schmerzpunkte vor dem Projekt:
- Der Founder hat in den wöchentlichen Sales-Reviews wiederkehrend Ad-hoc-Fragen, die das einzige Data-Team-Mitglied zwei bis fünf Tage Lead-Time kosten.
- Vertrieb, Finance und Produkt haben drei unterschiedliche Definitionen von „aktiver Kund:in”. Bei Quartalszahlen entstehen regelmässig Diskussionen über die „richtige” Zahl.
- Power BI Copilot funktioniert für einfache Dashboard-Fragen, scheitert aber an plattformübergreifenden Fragen wie „Welche Subscription-Kund:innen haben gekauft, aber noch keine Befragung veröffentlicht?”.
Das Ziel des Projekts: ein Slack-basierter Analytics-Agent, der mindestens 70 Prozent der wöchentlich wiederkehrenden Geschäftsfragen ohne Data-Team-Beteiligung beantwortet, mit auditierbarer Datenherkunft, in unter 30 Sekunden Antwortzeit.
Wir entscheiden uns für nao (getnao.io) als Open-Source-Framework, weil:
- Der Stack mit dem dbt-Repository und Postgres direkt funktioniert – keine Datenmigration.
- Der Context Stack als Files in Git lebt, also versionierbar, reviewbar, auditierbar.
- Wir den LLM-Anbieter offenhalten (Anthropic Claude für die Pilotphase, mit Option auf lokale Modelle für sensitive Bereiche).
- Die Lizenz und das Setup keine Pro-Sitz-Kosten erzeugen.
Die Datenlandschaft bei PulsCheck
Wir starten mit einem Inventar der vorhandenen Tabellen im Postgres-Warehouse (vereinfacht):
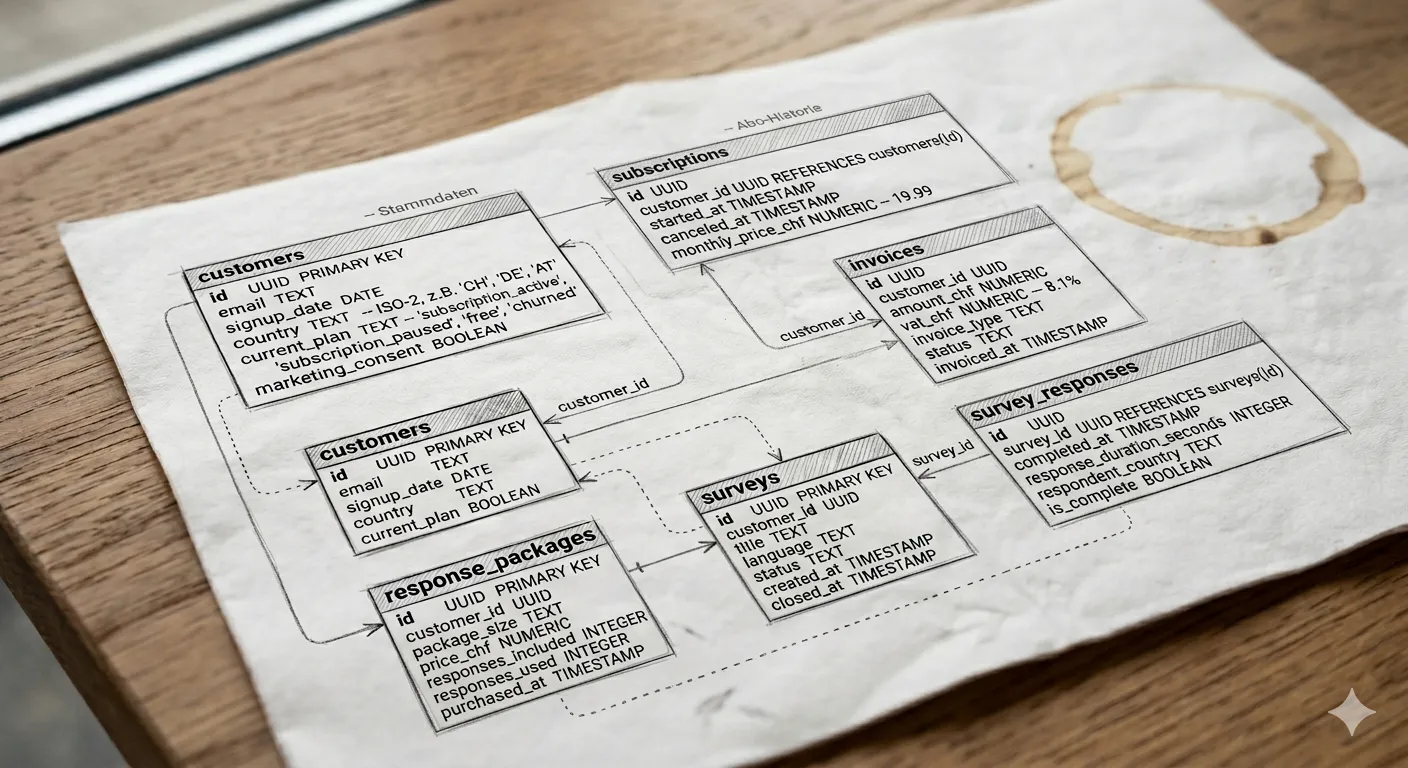
-- customers: Stammdaten
customers (
id UUID PRIMARY KEY,
email TEXT,
signup_date DATE,
country TEXT, -- ISO-2, z.B. 'CH', 'DE', 'AT'
current_plan TEXT, -- 'subscription_active', 'subscription_paused', 'free', 'churned'
marketing_consent BOOLEAN
);
-- subscriptions: Abo-Historie
subscriptions (
id UUID PRIMARY KEY,
customer_id UUID REFERENCES customers(id),
started_at TIMESTAMP,
canceled_at TIMESTAMP, -- NULL wenn aktiv
monthly_price_chf NUMERIC -- aktuell immer 19.99
);
-- invoices: Abrechnungen (Subscriptions UND Paketkäufe)
invoices (
id UUID PRIMARY KEY,
customer_id UUID,
amount_chf NUMERIC,
vat_chf NUMERIC, -- Schweizer MwSt 8.1%
invoice_type TEXT, -- 'subscription' oder 'response_package'
status TEXT, -- 'paid', 'failed', 'refunded'
invoiced_at TIMESTAMP
);
-- response_packages: gekaufte Antwort-Pakete (Pay-per-Use)
response_packages (
id UUID PRIMARY KEY,
customer_id UUID,
package_size TEXT, -- 'S', 'M', 'XL'
price_chf NUMERIC, -- 9, 19, 29
responses_included INTEGER, -- 5000, 10000, 100000
responses_used INTEGER, -- bisher tatsächlich verbraucht
purchased_at TIMESTAMP
);
-- surveys: erstellte Befragungen
surveys (
id UUID PRIMARY KEY,
customer_id UUID,
title TEXT,
language TEXT, -- 'de', 'fr', 'it', 'en'
status TEXT, -- 'draft', 'active', 'closed'
created_at TIMESTAMP,
closed_at TIMESTAMP
);
-- survey_responses: einzelne ausgefüllte Befragungen (verbrauchen Pakete)
survey_responses (
id UUID PRIMARY KEY,
survey_id UUID REFERENCES surveys(id),
completed_at TIMESTAMP,
response_duration_seconds INTEGER,
respondent_country TEXT,
is_complete BOOLEAN -- nur is_complete=true zählt fürs Paket
);Schon beim Inventar fällt auf, wo Definitionen driften können:
- „Umsatz” kann Subscription-Umsatz, Paket-Umsatz oder die Summe sein – brutto oder netto.
- „Aktive Kund:in” kann „Subscription läuft” oder „hat ein nicht-aufgebrauchtes Paket” oder „hat eine aktive Befragung publiziert” bedeuten.
- „Letzten Monat” ist ohne Zeitzonen-Definition mehrdeutig (Europe/Zurich vs. UTC).
- Gepauste Subscriptions zählen heute mal mit, mal nicht – je nach Report.
- Unvollständige Antworten (
is_complete = false) werden im Marketing manchmal mitgezählt, in der Abrechnungssicht nie.
Diese Mehrdeutigkeiten sind das eigentliche Problem. Der Agent verstärkt sie, wenn wir sie nicht vorher auflösen.
Schritt 1: Geschäftsfragen sammeln
Bevor wir Code schreiben, sammeln wir 25 reale Fragen aus den letzten zehn Wochen-Reviews und Slack-Chats. Auszug:
- „Wie hoch war der Monthly Recurring Revenue (MRR) Ende April?”
- „Wie viele Kund:innen haben wir im April verloren, und welcher MRR-Verlust war das?”
- „Welches Response-Paket hatte im Q1 den höchsten Umsatzanteil?”
- „Wie viele Subscription-Kund:innen haben im April kein einziges Response-Paket gekauft?”
- „In welcher Sprache wurden im April die meisten Befragungen veröffentlicht?”
- „Wie hoch ist der durchschnittliche Paket-Umsatz pro aktiver Kund:in im April?”
Diese 25 Fragen werden später unser Test-Korpus. nao empfiehlt im Evaluation Guide, genau so vorzugehen: erst die Fragen, dann der Context, dann die Iteration.
Schritt 2: nao installieren und initialisieren
Installation gemäss Quickstart:
pip install nao-core
nao initDas Resultat ist eine Projektstruktur, die in der nao-Dokumentation beschrieben ist:
pulscheck-analytics/ ├── nao_config.yaml # zentrale Konfiguration ├── RULES.md # Geschäftsregeln und Definitionen ├── agent/ │ ├── mcps/ # Model Context Protocols │ ├── skills/ # wiederverwendbare Skills │ └── tools/ # benutzerdefinierte Tools ├── databases/ # Schemas (nach sync befüllt) ├── docs/ # Dokumentation, inkl. synced Notion └── queries/ # Beispielabfragen
Schritt 3: nao_config.yaml ausfüllen
Wir öffnen nao_config.yaml und passen die Datenbankverbindung sowie die Anbieter-Konfiguration an.
project_name: pulscheck-analytics
databases:
- name: postgres-prod
type: postgresql
host: {{ env('PG_HOST') }}
port: 5432
database: pulscheck
user: {{ env('PG_USER') }}
password: {{ env('PG_PASSWORD') }}
llm:
provider: anthropic
api_key: {{ env('ANTHROPIC_API_KEY') }}
annotation_model: claude-3-7-sonnet-latestIm Grunde definieren wir hier in der minimal Konfiguration die Wahl unseres LLMs und die Datenbank an die wir uns andocken wollen. In einer erweiterten Konfiguration können wir auch mit einer accessors-Liste steuern, was nao über die Tabellen weiss: Spalten, ein Preview, Beschreibungen aus Kommentaren, statistisches Profiling. Das exclude-Feld kann genutzt werden um irrelevante Tabellen aus dem Context herauszuhalten. Das ist ein direkter Hebel auf Token-Kosten und Genauigkei: Die nao-Doku formuliert es so: „Too much context: higher token costs, slower responses, and confused answers from processing irrelevant information.”
Schritt 4: RULES.md – die kanonischen Definitionen
Hier entscheidet sich der Erfolg. Wir schreiben in RULES.md die Geschäftsregeln, die der Agent als Wahrheit behandeln soll. Auszug aus der PulsCheck-Version:
# PulsCheck - Agentenregeln
## Sprache und Zeitzone
- Antworten standardmässig auf Deutsch (Sie-Form), ausser explizit anders gefragt.
- Alle Datums- und Zeitangaben in Europe/Zurich, sofern nicht anders spezifiziert.
- "Letzter Monat" bedeutet der vorangegangene Kalendermonat in Europe/Zurich, vom 1. bis zum letzten Tag, 00:00-23:59:59.
## Währungen und Steuern
- Alle Geldbeträge in CHF, brutto inkl. 8.1% Schweizer MwSt, ausser ein Bericht erfordert explizit netto.
- Wenn netto verlangt: amount_chf - vat_chf.
## Metrik: MRR (Monthly Recurring Revenue)
- Definition: Summe der monthly_price_chf aller subscriptions,
bei denen started_at <= Stichtag UND
(canceled_at IS NULL OR canceled_at > Stichtag).
- MRR enthält ausschliesslich Subscription-Umsatz.
- Paket-Umsatz wird NIEMALS in MRR verrechnet.
- Bei Stichtag ohne Uhrzeit: 23:59:59 Europe/Zurich.
## Metrik: Paket-Umsatz (Response Packages)
- Definition: SUM(price_chf) aus response_packages für den abgefragten Zeitraum (basierend auf purchased_at).
- Refunds (invoices.status = 'refunded' UND invoice_type = 'response_package') werden abgezogen, wenn der refund-Zeitraum mit der Frage übereinstimmt.
## Metrik: Aktive Kund:in
- Standard-Definition für Berichte: current_plan = 'subscription_active' ZUM Stichtag.
- Wenn die Frage explizit Nutzung erwähnt: zusätzlich mindestens eine veröffentlichte Befragung (surveys.status IN ('active','closed')) ODER mindestens ein Paketkauf in den letzten 30 Tagen.
- Bei Mehrdeutigkeit: rückfragen, welche Definition gewünscht ist.
## Metrik: Churn (im Zeitraum)
- Definition: Anzahl subscriptions mit canceled_at IM Zeitraum UND started_at < Zeitraum-Beginn (also: war zu Beginn aktiv).
- Trial-Kund:innen (signup ohne aktive subscription) werden NICHT als Churn gezählt.
## Metrik: Befragungs-Antworten
- "Antworten" bedeutet standardmässig is_complete = TRUE in survey_responses.
- Unvollständige Antworten (is_complete = FALSE) NUR auf explizite Nachfrage.
- Eine Antwort wird gegen das zum Zeitpunkt aktive Paket des:der Survey-Eigentümer:in gerechnet (FIFO über response_packages).
## Tabellen-Hinweise
- invoices.invoice_type unterscheidet 'subscription' (monatliche Rechnung) von 'response_package' (Paketkauf). Niemals zusammenwerfen, ohne explizit zu summieren.
- response_packages.responses_used != survey_responses-Count: ersteres ist die Abrechnungssicht, letzteres die Event-Sicht. Können kurzfristig divergieren.
## Verhaltensregeln
- Bei jeder Antwort: SQL-Query und ungefähren Zeilenumfang nennen.
- Bei Beträgen unter 100 CHF Zweifel an Plausibilität aussprechen.
- Wenn eine Frage nur mit erheblicher Annahme beantwortbar ist: zuerst rückfragen.Diese Datei wächst über die Wochen. Wichtig ist, dass sie versioniert in Git lebt – jede Änderung ist nachvollziehbar, jede Regression auf einen Commit zurückführbar. Das ist einer der Punkte, den nao auch im Principles-Dokument als zentral hervorhebt: Context muss MECE sein – mutually exclusive, collectively exhaustive.
Schritt 5: Sync und Debug
nao debug
nao syncnao debug prüft Konfiguration, Datenbankverbindung, LLM-Zugriff. nao sync befüllt das databases/-Verzeichnis mit Schema, Spaltenbeschreibungen und Profiling-Statistiken, klont das dbt-Repo in repos/. Bei PulsCheck dauert das initiale Sync etwa vier Minuten.
Der databases/-Ordner enthält danach pro Tabelle eine Markdown-Datei mit Spalten, Typen, Sample-Werten und Profiling – maschinenlesbar für den Agenten und nachvollziehbar für uns.
Schritt 6: Erste Test-Suite
Wir legen einen tests/-Ordner an. Jede Testdatei ist eine YAML-Datei nach dem in der nao-Doku beschriebenen Schema:
# tests/mrr_end_of_april.yml
name: mrr_end_of_april
prompt: Wie hoch war der MRR Ende April 2026?
sql: |
SELECT SUM(monthly_price_chf) AS mrr_chf
FROM subscriptions
WHERE started_at <= '2026-04-30 23:59:59+02'
AND (canceled_at IS NULL OR canceled_at > '2026-04-30 23:59:59+02');
# tests/churn_april.yml
name: churn_april
prompt: Wie viele Kund:innen haben wir im April verloren, und wie viel MRR ging dadurch verloren?
sql: |
SELECT
COUNT(*) AS churned_customers,
SUM(monthly_price_chf) AS lost_mrr_chf
FROM subscriptions
WHERE canceled_at >= '2026-04-01 00:00:00+02'
AND canceled_at <= '2026-04-30 23:59:59+02'
AND started_at < '2026-04-01 00:00:00+02';
# tests/package_revenue_q1.yml
name: package_revenue_q1
prompt: Welches Response-Paket hatte im Q1 2026 den höchsten Umsatzanteil?
sql: |
SELECT
package_size,
SUM(price_chf) AS revenue_chf,
ROUND(100.0 * SUM(price_chf) /
SUM(SUM(price_chf)) OVER (), 1) AS share_pct
FROM response_packages
WHERE purchased_at >= '2026-01-01 00:00:00+01'
AND purchased_at < '2026-04-01 00:00:00+02'
GROUP BY package_size
ORDER BY revenue_chf DESC;
# tests/dormant_subscribers.yml
name: dormant_subscribers
prompt: Wie viele Subscription-Kund:innen haben im April kein einziges Response-Paket gekauft?
sql: |
SELECT COUNT(*) AS dormant_subscribers
FROM customers c
WHERE c.current_plan = 'subscription_active'
AND NOT EXISTS (
SELECT 1 FROM response_packages p
WHERE p.customer_id = c.id
AND p.purchased_at >= '2026-04-01 00:00:00+02'
AND p.purchased_at < '2026-05-01 00:00:00+02'
);Wir starten den Chat-Server und triggern die Tests:
nao chat # läuft auf http://localhost:5005
nao test # in einem zweiten Terminal
Schritt 7: Was wir beim ersten Test-Lauf gesehen haben
Erstes Resultat (Modell: anthropic:claude-sonnet-4-5, ohne weitere Iteration):
| Test | Pass/Fail | Tokens | Kosten | Dauer | Tool-Calls |
|---|---|---|---|---|---|
mrr_end_of_april | ✅ pass | 4’120 | $0.029 | 8.2s | 2 |
churn_april | ✅ pass | 5’480 | $0.038 | 11.4s | 3 |
package_revenue_q1 | ❌ fail | 6’210 | $0.043 | 13.1s | 4 |
dormant_subscribers | ❌ fail | 7’050 | $0.049 | 15.8s | 5 |
Was war das Problem bei package_revenue_q1? Der Agent hat nicht nur response_packages summiert, sondern fälschlich auch invoices mit invoice_type = 'response_package' einbezogen. Das führte zu Doppelzählung, weil ein Paketkauf sowohl als Event (in response_packages) als auch als Rechnung (in invoices) in zwei Tabellen liegt. Nichts in unseren Regeln verbot das explizit.
Was war das Problem bei dormant_subscribers? Der Agent hat „Subscription-Kund:innen” als „aktuell aktive Subscription” interpretiert – nicht als „im April durchgehend aktiv”. Er zählte also Kund:innen, die im April erst neu zugekauft hatten und in den verbleibenden Tagen kein Paket erworben hatten – das war nicht das, was der Founder meinte.
Schritt 8: Iteration – RULES.md schärfen
Wir ergänzen RULES.md:
## Wichtig: Paket-Umsatz - Single Source of Truth
- Die EINZIGE autoritative Quelle für Paket-Umsatz ist
`response_packages.price_chf`.
- `invoices` mit `invoice_type = 'response_package'` sind die Abrechnungssicht
der gleichen Käufe und dürfen NIEMALS additiv zu `response_packages`
verwendet werden.
- Für Cashflow-Sicht (bezahlt vs. offen) wird `invoices` verwendet,
aber dann ohne `response_packages`.
## Aktive Subscription "im Zeitraum"
- Wenn die Frage einen Zeitraum nennt (z.B. "im April"), bezieht sich
"aktive Subscription" auf Kund:innen mit:
`started_at < Zeitraum-Beginn`
**UND** (`canceled_at IS NULL` **ODER** `canceled_at > Zeitraum-Ende`).
- Also: Kund:innen, die den GANZEN Zeitraum aktiv waren.
- Wenn die Frage einen Stichtag nennt: Aktivität zum Stichtag.Wir fügen ausserdem eine Beispielabfrage in queries/dormant_subscribers.sql hinzu, damit der Agent einen Referenzpfad sieht:
-- queries/dormant_subscribers.sql
-- Use case: Subscription-Kund:innen, die im Zeitraum X aktiv waren,
-- aber KEIN Response-Paket in diesem Zeitraum gekauft haben.
-- Erwartet: COUNT(*) - eine einzige Zahl.
SELECT COUNT(DISTINCT c.id) AS dormant_subscribers
FROM customers c
JOIN subscriptions s ON s.customer_id = c.id
WHERE s.started_at < :period_start
AND (s.canceled_at IS NULL OR s.canceled_at > :period_end)
AND NOT EXISTS (
SELECT 1 FROM response_packages p
WHERE p.customer_id = c.id
AND p.purchased_at >= :period_start
AND p.purchased_at < :period_end
);Zweiter Test-Lauf nach Anpassung von RULES.md und Hinzufügen der Beispielquery:
| Test | Pass/Fail | Tokens | Kosten | Dauer |
|---|---|---|---|---|
mrr_end_of_april | ✅ pass | 3’980 | $0.027 | 7.5s |
churn_april | ✅ pass | 5’310 | $0.036 | 10.9s |
package_revenue_q1 | ✅ pass | 5’870 | $0.041 | 11.7s |
dormant_subscribers | ✅ pass | 6’420 | $0.045 | 13.2s |
Aussagekräftiger als die Pass-Rate ist der Token-Verbrauch: er sinkt durchgängig, weil der Agent weniger explorative Abfragen braucht. Genau das ist das Versprechen der nao-Principles: „Each exploratory query costs money and time. Well-documented context reduces the need for trial-and-error queries.”
Schritt 9: Slack-Integration und Web Interface
Damit das Team Fragen direkt im Arbeits-Messenger stellen kann, lässt sich nao nativ an Slack anbinden – über einen slack-Block in nao_config.yaml mit Bot-Token und Signing-Secret. Nach Re-Sync ist der Bot in privaten Channels via @-Mention ansprechbar und liefert seine Antworten inklusive SQL-Query und Datenherkunft, was die Auditierbarkeit erhält.
So sieht dann eine typische Konversation mit nao aus. Wir können in jedem Request nachvollziehen welche SQL Queries gemacht worden sind und welche Datenbanktabellen untersucht worden sind. Auch eine prediction in die Zukunft ist möglich mit einfachen Hausmitteln wie der linearen Regression.
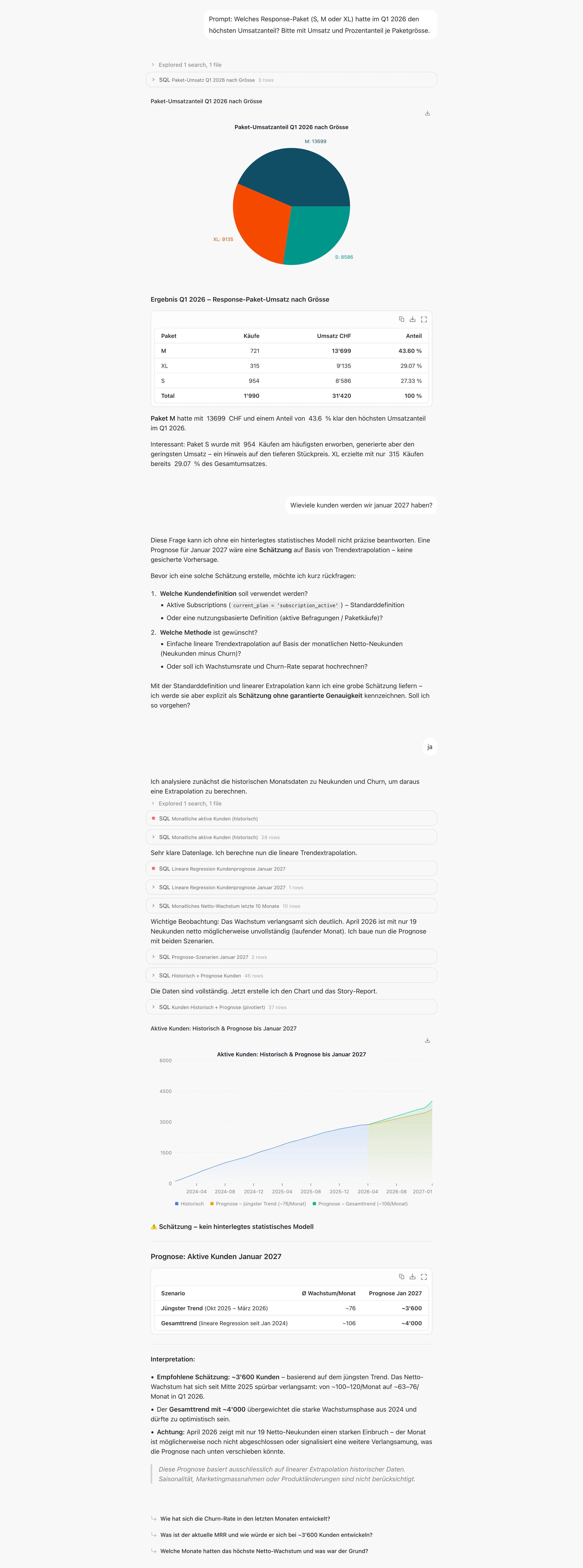
Schritt 10: Auditierbarkeit
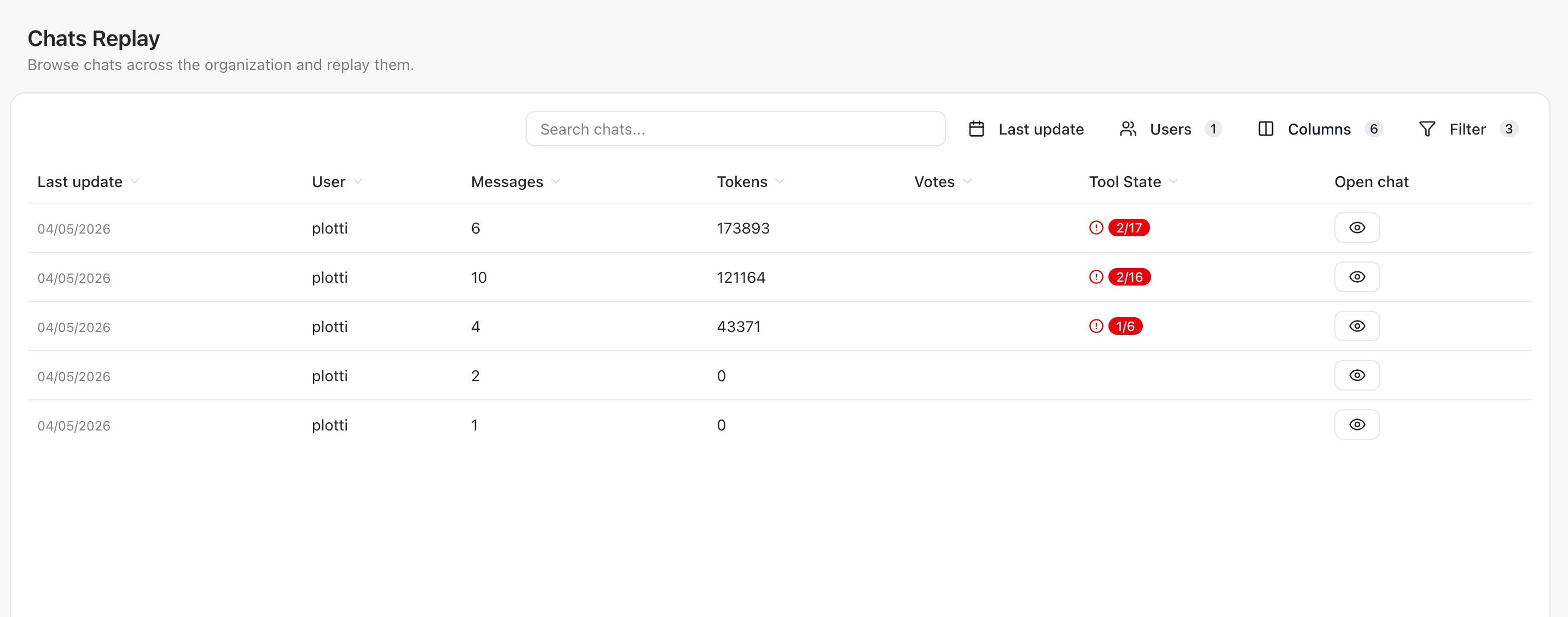
Nao erlaubt es alle bisher geführten Chats durch ein Team oder einen Admin einzusehen, so kann im Prinzip überprüft werden ob die Antworten korrekt und sauber waren. Allerdings skaliert eine solche manuelle Überprüfbarkeit nur bedingt, da ja jeder Request auch logisch nachvollzogen werden muss. Daher ist der automatische Test basierte Ansatz durchaus attraktiv, da er zumindest die wichtigsten Use-Cases Covern kann die immer wieder angefragt werden.
Wo nao an seine Grenzen kommt
- Skill-Anforderung im Team: Wer dbt, YAML und Test-Disziplin nicht kennt, kommt mit nao nicht weit. Eine Plattformlösung wie Snowflake Cortex Analyst, ThoughtSpot oder Power BI Copilot ist initial niederschwelliger.
- UI-Reife: Das Chat-UI ist funktional, aber nicht so poliert wie ein kommerzielles Produkt. Für viele KMU-Kontexte (Slack, Teams) ist das egal, weil ohnehin in den Messengern gearbeitet wird.
- Multi-Workspace-Governance: nao ist projektzentriert. Wer fünf Geschäftsbereiche mit jeweils eigener Rechte-Matrix bedienen will, braucht zusätzliche Architekturarbeit.
- Self-Hosting-Operating: Wer keine eigene Infrastruktur betreiben will, sollte den nao-Cloud-Service prüfen oder zu einer fully-managed Alternative greifen.
Wann eine andere Lösung passt
Die Agentic-BI-Landschaft ist 2026 schnell gewachsen. Im Folgenden ein nüchterner Überblick über die Alternativen, die für Schweizer KMU realistisch in Frage kommen – ohne Anspruch auf Vollständigkeit.
Native Plattform-Lösungen
Snowflake Cortex Analyst und Cortex Agents sind die naheliegendere Wahl, wenn Ihre Daten ohnehin in Snowflake liegen. Cortex Analyst übersetzt natürliche Sprache in SQL gegen einen YAML-basierten Semantic Layer (Snowflake nennt das „Semantic Views”), Cortex Agents orchestrieren darüber Tool-Use auch über unstrukturierte Daten via Cortex Search (Snowflake-Dokumentation). Vorteil: Daten verlassen den Snowflake-Sicherheitsperimeter nicht, RBAC wird respektiert, kein zusätzliches Hosting. Nachteil: Plattformbindung an Snowflake, Kosten skalieren mit Token- und Compute-Verbrauch.
Microsoft Power BI Copilot und Fabric Data Agents sind die pragmatische Wahl, wenn Sie ohnehin tief im Microsoft-Ökosystem stecken und ein gepflegtes Power-BI-Semantic-Model existiert. Für Standard-Reporting innerhalb dieses Modells liefert Copilot heute solide Ergebnisse. Sobald Fragen plattformübergreifend werden oder der Semantic Layer offen bleiben soll, stösst Copilot an Grenzen.
Databricks Genie spielt seine Stärke aus, wenn ein Lakehouse mit Unity Catalog steht und sowohl ML- als auch BI-Workloads bedient werden müssen.
Etablierte BI-Plattformen mit Agentic-Erweiterung
Sigma Computing (sigmacomputing.com) ist eine warehouse-native BI- und AI-Apps-Plattform mit Spreadsheet-UX. Sigma fragt direkt gegen Cloud-Warehouses (Snowflake, Databricks, BigQuery, Redshift) und ergänzt das Bild um Sigma Agents für Workflow-Automation. Sigma wurde 2025 als Snowflake BI Data Cloud Product Partner of the Year ausgezeichnet und ist im Gartner Magic Quadrant für Analytics & BI 2025 als Visionary geführt. Geeignet vor allem für Teams, die bereits in einem Cloud-Warehouse arbeiten und eine spreadsheet-vertraute Oberfläche mit Enterprise-Governance, Embedded Analytics und Writeback-Funktionen kombinieren möchten. Eher Mittelstand bis Enterprise als KMU-Einstiegsoption.
ThoughtSpot (thoughtspot.com/de) positioniert sich seit Jahren als Search-driven BI-Plattform und hat den Stack 2025/2026 zur Agentic Analytics Platform ausgebaut: „Spotter” als KI-Analyst, SpotterModel für automatisierte semantische Modellierung, SpotterViz für agentengenerierte Dashboards und SpotterCode für KI-gestütztes Embedded-Development. ThoughtSpot wird im Gartner Magic Quadrant 2025 als Leader geführt. Mit deutschsprachiger Website und Schweizer/DACH-Präsenz eine ernstzunehmende Option für Mittelstand und Enterprise, die natürlichsprachige Suche, Embedded Analytics in eigenen Produkten oder eine fertig integrierte Spotter-Plattform suchen. Lizenzkosten sind allerdings deutlich höher als bei Open-Source- oder Pay-as-you-go-Lösungen.
Spezialisierte AI-Data-Analyst-Tools
Basejump AI (basejump.ai) ist ein „Chat-with-your-data”-Agent mit Schwerpunkt auf KMU- und Mid-Market-Setups. Der Anbieter setzt auf Trust Scores und crowdsourced Human Verification, um Halluzinationen messbar zu reduzieren. Daten verbleiben in der eigenen Datenbank, generierte SQL-Queries sind transparent einsehbar und auditierbar, und die Plattform bringt eine API für Embedded- und White-Label-Use-Cases. Eher geeignet für KMUs, die schnell mit einer schlanken Plattform starten und dabei ein Governance-Modell mit menschlicher Verifikation aufbauen möchten – ohne den Eigenbau-Aufwand eines nao-Stacks.
BlazeSQL (blazesql.com) ist ein SQL-orientierter AI-Data-Analyst, der die Datenbankstruktur automatisch extrahiert und in den Tools antwortet, in denen das Team ohnehin arbeitet (Slack, Microsoft Teams, ChatGPT, Claude). BlazeSQL unterstützt eine breite Palette an Datenbanken (Snowflake, BigQuery, Microsoft SQL Server, PostgreSQL, MySQL, Redshift, Databricks, ClickHouse u. a.), bietet eine Desktop-App mit Offline-Modus für lokale Datenresidenz sowie einen White-Label-/Embed-Modus. Das Unternehmen sitzt in Luxemburg, was für DACH-Kund:innen den EU-Datenraum-Vorteil mitbringt. Pragmatische Wahl für lean Teams, die primär einen funktionierenden SQL-Chatbot brauchen, ohne ein komplettes BI-Stack-Setup aufzubauen, und die Wert auf Datenschutz mit Offline-Option legen.
Worauf es bei der Auswahl ankommt
Vier Kriterien helfen, die richtige Lösung zu finden:
- Datenresidenz und EU-/CH-Konformität: Wo liegen Ihre Daten, wo läuft das Modell, wo werden Anfragen gespeichert?
- Auditierbarkeit: Können Sie pro Antwort nachvollziehen, welche Definitionen, Quellen und SQL-Queries einflossen?
- Anpassbarkeit der Geschäftslogik: Bleibt Ihr Semantic Layer offen lesbar, oder ist er im Vendor-Format gefangen?
- Exit-Kosten: Was kostet es Sie in drei Jahren, wieder auszusteigen oder den Anbieter zu wechseln?
Reifegrad-Check für Ihr Unternehmen
Bevor Sie ein Agentic-BI-Projekt starten, prüfen Sie diese fünf Punkte:
- Datenmodell: Existiert ein zentrales, dokumentiertes Datenmodell – oder leben Daten verteilt in operativen Systemen?
- Metrik-Konsistenz: Sind die wichtigsten 20 Geschäftsmetriken so definiert, dass alle Bereiche dieselben Zahlen rechnen?
- Lineage: Können Sie für eine Kennzahl nachvollziehen, welche Quellen mit welcher Logik einfliessen?
- Abfragbare Schicht: Liegt Ihr Datenfundament in einem Data Warehouse oder Lakehouse, idealerweise mit dbt oder vergleichbarer Transformation?
- Pflegekapazität: Hat Ihr Team Kapazität für einen wöchentlichen Pflege-Rhythmus – neue Definitionen, Test-Updates, Anpassungen an Geschäftsänderungen?
Wenn weniger als drei dieser Punkte mit „ja” beantwortet werden können, ist die ehrliche Empfehlung, mit dem Datenfundament zu beginnen, nicht mit dem Agenten. PulsCheck hatte vor dem Projekt vier von fünf Punkten erfüllt – das ist erfahrungsgemäss die Voraussetzung dafür, dass ein Aufbau in vertretbarer Zeit gelingt.
Fazit
Drei Erkenntnisse aus diesem Beitrag:
Erstens: Agentic BI ist kein Ersatz für Datenarbeit. Es macht ihre Qualität sichtbar. Wo das Fundament hält, liefert das System überraschend gute Ergebnisse. Wo es bröckelt, wird das schneller offenbar als in jedem Dashboard.
Zweitens: Der Semantic Layer und die Geschäftsregeln in RULES.md (oder dem Äquivalent Ihrer gewählten Plattform) sind nicht Detail – sie sind der Kern. Bei PulsCheck war jede Verbesserung der Antwortqualität auf eine Schärfung der Regeln zurückzuführen, nicht auf einen Modellwechsel.
Drittens: Realistischer Zeithorizont für ein KMU mit reifem Datenfundament sind sechs bis zwölf Wochen bis zur ersten produktiven Nutzung, sechs bis zwölf Monate bis zur betrieblichen Reife mit echtem Vertrauen.
Der nächste sinnvolle Schritt ist nicht der Tool-Vergleich. Es ist der ehrliche Reifegrad-Check Ihres Datenfundaments und das Sammeln der 25 wichtigsten Geschäftsfragen, die heute Ihr Data-Team blockieren.
Quellen und weiterführende Ressourcen
Open Source nao:
- getnao/nao auf GitHub – Source Code, MIT-Lizenz
- nao Quickstart Guide
- Context Engineering Principles
- Evaluation Guide
- nao Blog: How to Build a Context Stack for Agentic Analytics
Native Plattform-Lösungen:
- Snowflake Cortex Analyst Documentation
- Snowflake Cortex Agents Documentation
- Snowflake Engineering Blog: Cortex Analyst Text-to-SQL Accuracy
- Microsoft Fabric Data Agents Overview
- Databricks Genie Documentation
Etablierte BI-Plattformen mit Agentic-Erweiterung:
- Sigma Computing: sigmacomputing.com – Architektur-Übersicht: Warehouse-First Architecture
- ThoughtSpot: thoughtspot.com/de – Agenten-Übersicht: BI-Agenten
Spezialisierte AI-Data-Analyst-Tools:
- Basejump AI: basejump.ai – Produktdoku: docs.basejump.ai
- BlazeSQL: blazesql.com – Hilfecenter: help.blazesql.com
Hintergrund:
- Databricks Blog: Why Agentic Analytics Starts with a Well-Governed Data Layer (April 2026)
- dbt Labs: dbt Semantic Layer
- Cube: Universal Semantic Layer
Dieser Beitrag basiert auf einer zusammengesetzten Fallstudie aus Schweizer KMU-Projekten. Die Datapeople-Datenredaktion arbeitet mit Schweizer KMU an Datenarchitektur und Analytics. Feedback an hello@datapeople.ch.